Free Player Retention Guide Get Now
The previous post on model drift highlighted the need to rebuild models as frequently as needed. How would this be done in practice? The most obvious path would be to have the data scientist rebuild the model, including generating the training dataset, model fitting, testing and comparison. Once the new model is completed, the next step would be to swap out the old model with the new model in a production environment.
Imagine now if the model needs to be refreshed on a weekly basis. Does that mean one data scientist is needed to maintain one model? After several rounds of model refresh and deploy, she would probably want to automate the process. Here's where automated tools come in handy.
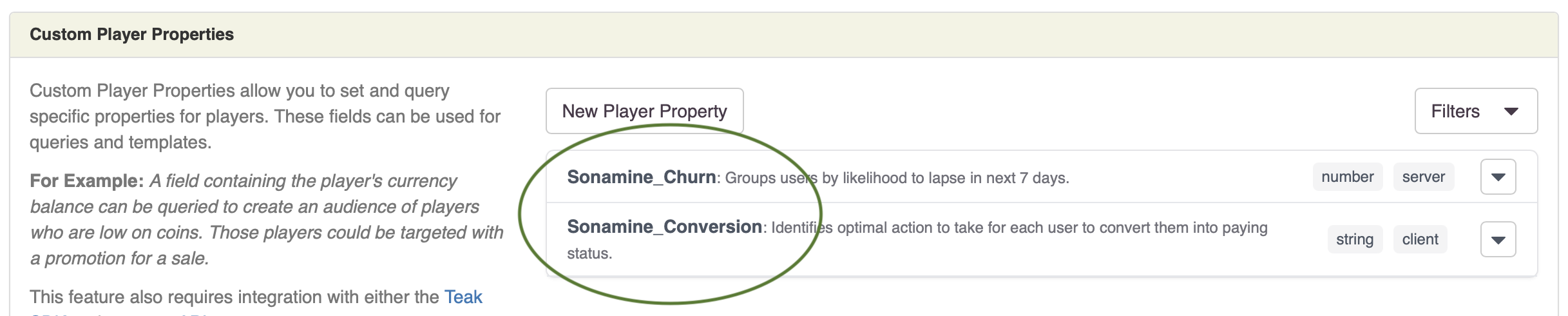
The first step is to divide up the model refresh into discrete steps. A simple version could like figure 1.

The first step is usually generating the dataset needed for rebuilding. Putting aside the possibility of new data for the moment, automating dataset generation would likely involve running some query scripts on a compute engine. The output should be stored along with the metadata associated with the dataset.
The second step is the rebuild the model. Most modern models utilize ensemble methods, so many algorithms are used. All the usual steps such as feature engineering and hyper-parameter tuning occur here. Similar to the dataset generation, modeling output should be stored along with metadata associated.
The third step is a model comparison step. Several model fitness criteria may be used to determine the "best" model for the application. As described in the previous post, it may be a regression between predicted and actual; or more broad measures such as accuracy and precision. The output of the step is a determination of which model to use for production scoring.
The final step is a propagation to the production line. Once the champion model has been selected, it must to used to generate production scores. If deployment is a real time scorer, then the real time scoring code should be generated and tested in a standard CI framework. A more batched process still requires a testing step, where a batch of scores must be produced with both the current and new champion model.
The key to automation is a fault tolerant job scheduler that can manage each of the steps. If dataset generation can be scheduled to run on a daily or ad-hoc basis, that would alleviate the manual processes of dataset generation. The same logic applies to the other jobs. Most commonly, teams start with cron jobs. We recommend against this approach, for reasons detailed later in this post.
Another common approach is to leverage the scheduler that is built into different tools separately. For example Google has various scheduling functions built right into BigQuery. Other modeling tools like RStudio Connect have their own scheduling capabilities. We also recommend against this approach, for reasons detailed later as well.
Sonamine experiences have highlighted these key scheduler functionalities for modeling automation:
Automation separates the winners from the rest, according to a McKinsey survey of AI in 2020. Automation is a core foundational principle behind the Sonamine predictive scoring service, allowing our customers to use AI in CRM without a large initial investment. What's your automation strategy? Contact us to compare notes!
Subscribe to our monthly newsletter to get all our content.
Reference
1. https://www.mckinsey.com/business-functions/mckinsey-analytics/our-insights/global-survey-the-state-of-ai-in-2020
For a limited time until December 2025, Sonamine is offering a 60 day money back guarantee to OneSignal customers. Come experience the ease and simplicity of the First Time Spender Nudge package and watch your conversions soar.
For a limited time until December 2025, Sonamine is offering a 60 day money back guarantee to OneSignal customers. Come experience the ease and simplicity of the First Time Spender Nudge package and watch your conversions soar.