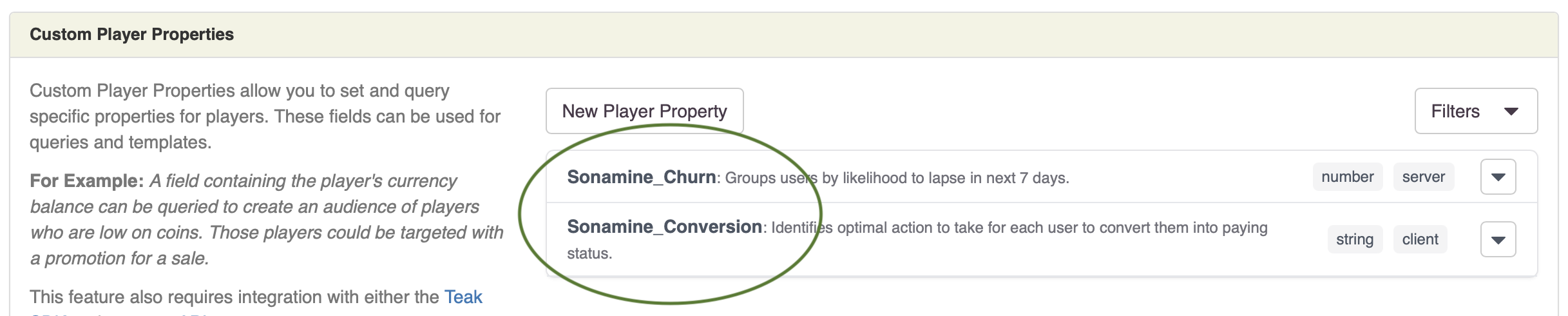
Free Player Retention Guide Get Now
A common cousin to game analytics is AB testing. Many analytics tools such as Upsight are beginning to offer native AB testing capabilities within their suite.
As a quick introduction, to run an AB test, you split players into two groups. For one group (A) you do something with them; for the other group (B) you do something else. Something else could mean do nothing. Then you compare the metrics of these two groups to see if there are differences. You can have multiple groups of course. For example, you give the A group some free gifts while leaving the B group alone; then you compare the spending and retention of the two groups. If group A has 20% 14-day retention while B has 15% 14-day retention, we make the claim that free currency improves retention.
My 6 year old company Sonamine offers player predictions so our customers like to run AB tests to see if these predictions improve monetization and retention. Here are some lessons learned from designing these A-B tests and interpreting the results.
AB tests assume that the two groups are identical, which allows you to make the claim that your test caused the improved results. However, many teams we have worked with forget to check that the groups have similar characteristics. To do this you just need to compare the characteristics of the two groups. Look at the revenue spent, the playtime, days since their first play, country, etc. Make sure they look the same for the two groups. In the above example, you can compare the 7 day retention chart for the groups.

If the chart looks like this one above, then you know the group A already is retaining better and your free currency might not be that helpful.
AB tests also assume that the groups are really getting different treatments. Said differently, to make the claim of effective test, you have to make sure that the special treatment is not "leaching" across to multiple groups. This is a "contamination" issue and is particularly difficult for games that are very social in nature or have a vocal community.
Taking the example of free currency above. Let's say you message the group A players and give them a coupon code for free currency. If the coupon code is not specific to each player, then group A players might share that code with the group B players. This can easily happen through chats, forums, or just plain player-to-player messages. To avoid this you could make the test as difficult to share as possible just for the AB test, perhaps use a player specific code. You should also check to see if the group B players redeemed the code given to group A.

In addition to direct contamination as shown in the graphic above, indirect contamination can also occur. In the above example, the group A players might use the free currency to buy certain items, which they then gift to their friends in group B. To mitigate this it's best to select group A and B such that they have as few ties as possible. Look for guild membership, previous chat trade gift PvP joint-quest histories and make sure A and B groups truly do not mix.
After the test is completed and you are looking at how the groups are different, most tools will let you compare the absolute metrics. What were the retention, engagement and monetization KPIs for the two groups? But most of these tools do not let you easily compare the % change in the KPIs. This is absolutely critical when the KPIs are changing over time.
As an example, let's say churn in group B increased by 56%, while group A saw churn increase by 36%. This means that the group A treatment reduced the natural churn by 30%! This is not a small amount. There is an actual study with these numbers and churn reduction at this gamaustra blog post.
By now everyone asks whether there is "statistical significance" in any test. In brief, statistical significance measures how likely you are to be tricked into thinking there was a true effect when there's none. So a 5% significance means there is less than 5% chance that there is no effect even though the test shows an effect.
What is usually missed is the concept of effect size. Effect size really refers to the impact of the test. Here you need to exercise human judgement to determine if the effect size is "worth it". If a test increases overall revenue by 0.1%, it can be very statistically significant but have almost no positive impact.
A good example is the aspirin-heart attack study. Aspirin was found to relate with fewer heart attacks at a significance level of 0.001%. So patients were advised to take aspirin. Further analysis of the results showed the effect size was very very very tiny, with the difference in heart-attack risk of only 0.77% Turns out the patients were getting more side effects from the aspirin. While researchers now admit the flaws in the interpretation, many patients are still taking aspirin daily...
In games, we have witnessed cases where really awesome effect sizes were ignored because they were not significant at the 5% mark. For example, an effect size that created "10% more conversions in free-to-play games" is a really great impact. For this type of effect size, I'd be willing to act on this test result as long as the significance is less than 30%. Why? Because the 10% more conversions is such a large impact.
You can further feel better about this type of effect size-significance trade off by running the same test a few more times.
Happy testing!
More reading
For a limited time until December 2025, Sonamine is offering a 60 day money back guarantee to OneSignal customers. Come experience the ease and simplicity of the First Time Spender Nudge package and watch your conversions soar.
For a limited time until December 2025, Sonamine is offering a 60 day money back guarantee to OneSignal customers. Come experience the ease and simplicity of the First Time Spender Nudge package and watch your conversions soar.