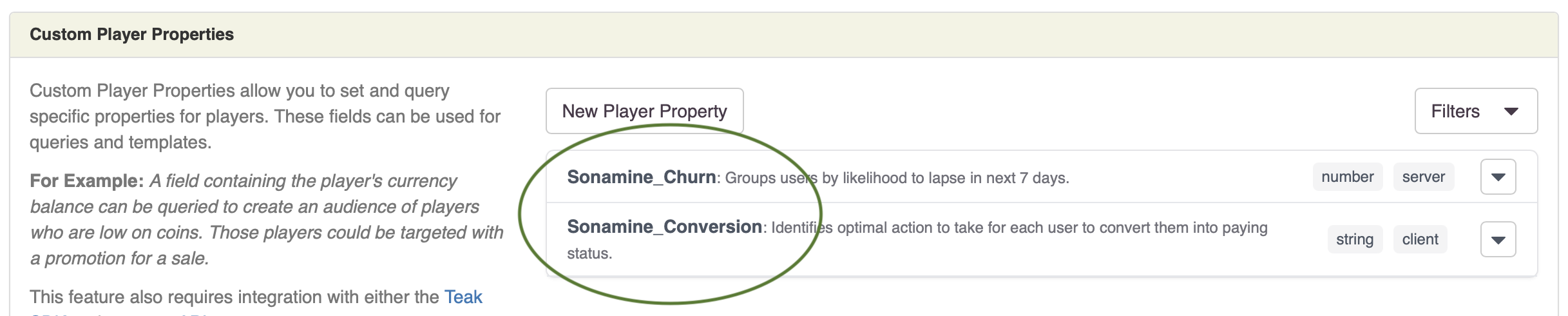
Free Player Retention Guide Get Now
Last Friday, I had the pleasure to attend an all day symposium titled "Societal Impact through Computing Research". One keynote speaker was Ed Felten, deputy CTO of the United States. To the audience, he posed three challenges regarding the use of big data and computing:
Each of these challenges resulted in a lively and energetic discussion. In this series of blog posts, I will discuss these 3 challenges from the perspective of analyzing the use of a game or app. The reader should be fairly familiar with games, apps, mobile marketing and analytics. Let's start with methodological biases and flaws.
Why you should care about biases and flaws
Biases and flaws in big data methodologies will lead you to incorrect conclusions. If you are striving to be or already are data-driven, incorrect data-driven conclusions will lead you to inappropriate and costly decisions and actions. If your data driven decisions are automated or algorithmic, the negative effects of incorrect conclusions are further magnified as no one reviews them. More on this in the next post, but for now, it is imperative that biases and flaws be fixed.
Correlation does not always equal causation
Most introductory statistics courses highlight that correlation does not equal causation. It is not clear, however, how well understood this concept is within the game developer community. We are prone to looking for the simple answer. So when we find that users who received at least 6 notifications correlated highly with 7-day retention, the natural assumption is to say that "sending users 6 notifications" will cause them to be retained.
Complicating matters is that the tools to find novel but possibly meaningless correlations are getting easier to use. In fact, the example above is taken from Amplitude's growth discovery engine documentation. This feature allows you to find correlations in the data that apps send to their analytics service.
Correlations are useful as starting points to investigate further. If it turns out that one type of notifications being sent to users included level up or resource building completion events, then it makes sense that retained users had lots of notifications. You found a spurious correlation and avoided an ill-advised retention program based on large numbers of notifications.
How then do we ascertain causation? There are many mathematical techniques, none involving only correlation; and the gold standard in clinical trials is the "randomized double blind placebo control study", which you might call the "randomized double blind A/B test" in games.
Generalizing findings is tricky
When you find something interesting analytically, the temptation is to generalize it and say it applies to all users. For the retention example above, if you found the correlation from users who started playing in June (again from the Amplitude documentation), you may think this correlation applies to all users before and after June. This is an expedient and convenient assumption. So what's wrong with that?
If the conditions of the findings are identical or very similar to the overall circumstances, you will be able to generalize the findings. In the retention example, you are assuming that the June users are similar to non-June users, and that external conditions, such as the presence of competing games or seasonality, are more or less the same. However, in practice, users are different from month to month due to user acquisition strategies. For example, most games and apps are launched in various countries at different times. Also, users obtained in the early part of the game lifecycle are noticeably different in their behaviors from later stage users.
So how do you generalize your findings? Cautiously and only after extensive comparison of the study group and the overall generalization population. Check to see if key metrics have the same overall frequency distribution (don't use averages) between the study group and the generalization group. These include languages, country, monetization rates, engagement level, level progression rates, virtual currency spend-down and earn rates. Compare the external circumstances of the study group and generalization group: did you run a promotion during the study period, is your game targeted at students who play more during summer holidays? Only after you are convinced that the study group is very very similar in as many ways as possible to the generalization group can you be confident of the generalization.
Bounded rationality and tunnel vision
Daniel Kahneman, a Nobel prize laureate in economics, coined the term "What you see is all there is" to describe our tendency not to look for additional information before generating conclusions. In the previous small data era, there was little reason to ask the question of "what else are we not looking at" as you couldn't get the required data. With big data, you can feasibly examine more data points to inform your conclusion. A simple example is to incorporate weather information into your reports. People are outdoors when the weather is nice and vice versa; and this affects their app usage and game play pattern.
This bias is further worsened because initial conclusions suffer from the anchor bias. These conclusions become the "correct" ones that we know; it is harder to question or re-examine them in different ways. Additionally, new findings will be view in comparison to these initial conclusions. In other words, it's hard to keep an open mind once we accept the first conclusions.
Solutions to these interpretive biases and flaws
What you notice throughout this discussion is that these biases and flaws are not really due to statistics or math, but rather to how we interpret the methods or results. So the solution to these biases and flaws is not technical, but human.
When I led analytic teams focused on generating actionable insight from data, we would use a standard "findings template" to avoid these issues. Within the "findings template" are questions specifically focused on these 3 biases - causality assumptions, generalizabilty of findings, and consideration for alternative hypotheses.
Increasing awareness and mitigating these issues through peer review or weekly presentations is another way to establish an analytic culture where these biases and flaws are surfaced and addressed. Just as code reviews are a standard best practice for development, analytic finding presentations should added as a best practice.
It also makes sense to put a time-to-live (TTL) on analytic findings and conclusions. All business cases should include the TTL of the underlying analytic results and assumptions. This way, decision makers can make their own determination on the confidence of the underlying analytic assumptions.
The appropriate training materials for incoming data analysts or data scientists would also go a long way to establishing the right cultural foundation to address these biases and flaws.
Unfortunately, the solution is not a one time solution, like a software feature. It takes continuous effort and investment. I'd love to hear your feedback, either comment below, contact me.
For a limited time until December 2025, Sonamine is offering a 60 day money back guarantee to OneSignal customers. Come experience the ease and simplicity of the First Time Spender Nudge package and watch your conversions soar.
For a limited time until December 2025, Sonamine is offering a 60 day money back guarantee to OneSignal customers. Come experience the ease and simplicity of the First Time Spender Nudge package and watch your conversions soar.